We have built some of the world’s largest real-time data processing pipelines and have expertise across AWS and open source technologies. Our data pipelines are optimized for data throughput and also for queries so users no longer have to wait hours for reports to run and can provide ongoing management and optimization.
Simple data validation before it hits your data pipeline
The adage of “fail fast, fail hard” is never more accurate than when trying to load and process large volumes of data. Although more subtle issues need be handled later in the data pipeline during data processing and cleansing, there are several simple tests data engineers can run as soon as a batch of data is received. Some of these can even run before the data files are opened. With automated data delivery it’s surprising how many simple things can go wrong: zero length files, missing files, unexpected files, last week’s files, massively bloated files. Over the years we’ve seen them all. That’s why at Dativa our data engineers have developed tools to detect rogue data as soon as we receive it.
Best Practice Data Architectures in 2017
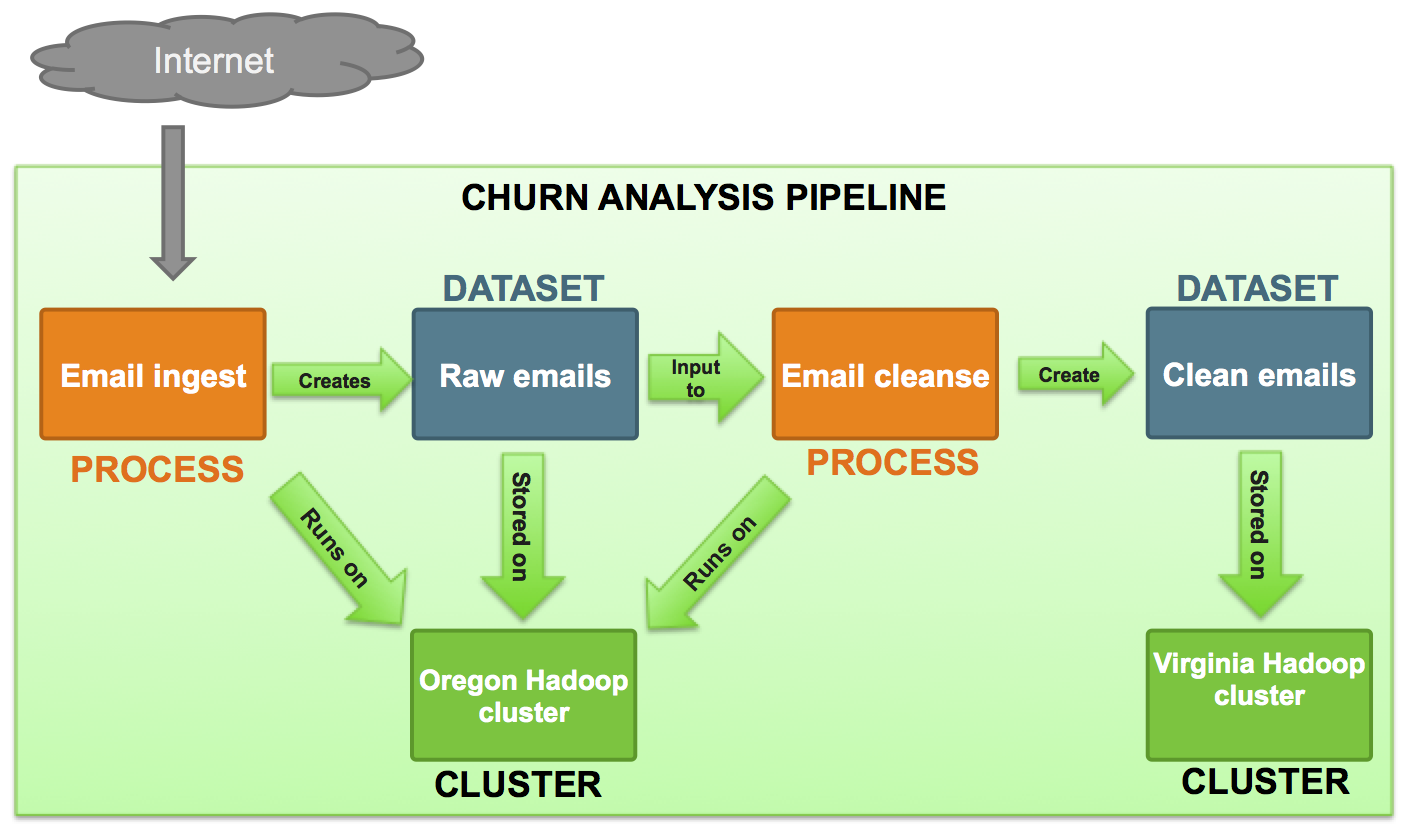
With an ever-increasing number of technologies available for data processing and three highly competitive cloud platform vendors, we at Dativa have to stay on top of exactly what are the best technology choices for our clients. Most of the work we undertake involves processing and loading data into a data lake, provide post-processing on top of that, and then reporting on it. We’ve developed a standard data processing pipeline architecture that covers both historical data analysis in a data lake and also real-time data processing through a separate stream.
Data warehouse upgrade
A customer had developed a data pipeline based on AWS technology that was becoming slow as their client based scaled. As well as being slow, the system was also costly because it relied on expensive infrastructure – in this case, Redshift DC nodes – to provide a brute force solution to the data loading and analysis problem. The engineering team that had initially built the platform was engaged in other new product development features and did not have time to revisit this project. We’re hired to review the technical solution, re-design the database from the ground up, and deliver a new platform. We continued with an AWS solution, this time based on Redshift DS nodes, which are significantly more cost-effective, and we optimized the database schema to make better use of Redshift’s distribution and sort keys to ensure the most efficient use of the available hardware. By the time we had completed the migration, we had reduced the client’s hosting costs, fixed the throughput problems, and also enabled more sophisticated queries and analysis on the database. The hosting costs can subsequently scale exponentially, and only a few design changes can make significant reductions in cost. The client spent the costs saved on hosting on establishing an offshore DBA service where we operate providing pro-active database optimization, remote query support, troubleshooting and database updates.